CEREMA Île-de-France · Internship Project
Internship Hydrology
Workflow
Python pipeline developed during my internship at CEREMA to clean, resample, and analyse rainfall/flow/storage time series — estimating dry-weather baseflow and separating rainfall-induced flow from raw sensor data.
Overview
What the workflow does
Raw sensor exports from CEREMA field sites contain irregular timestamps, missing value codes (−6999 / −7999), and mixed rainfall, flowrate, and storage tank data in a single semicolon-separated file. This pipeline automates the full path from raw export to clean diagnostic figures, ready for model calibration.
Outputs
Example figures
These figures are generated from the 30-minute resampled time series. Raw input data are not included in the repository (field site data, confidential).
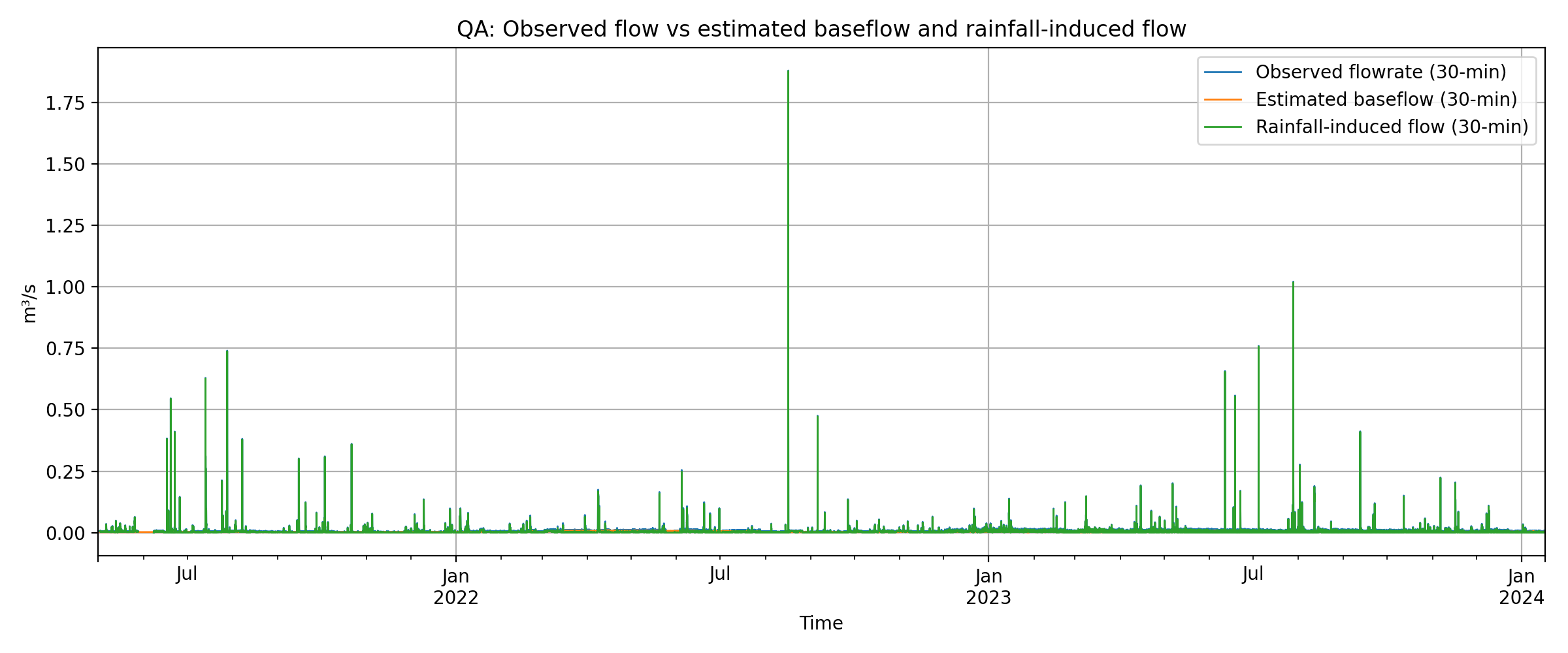
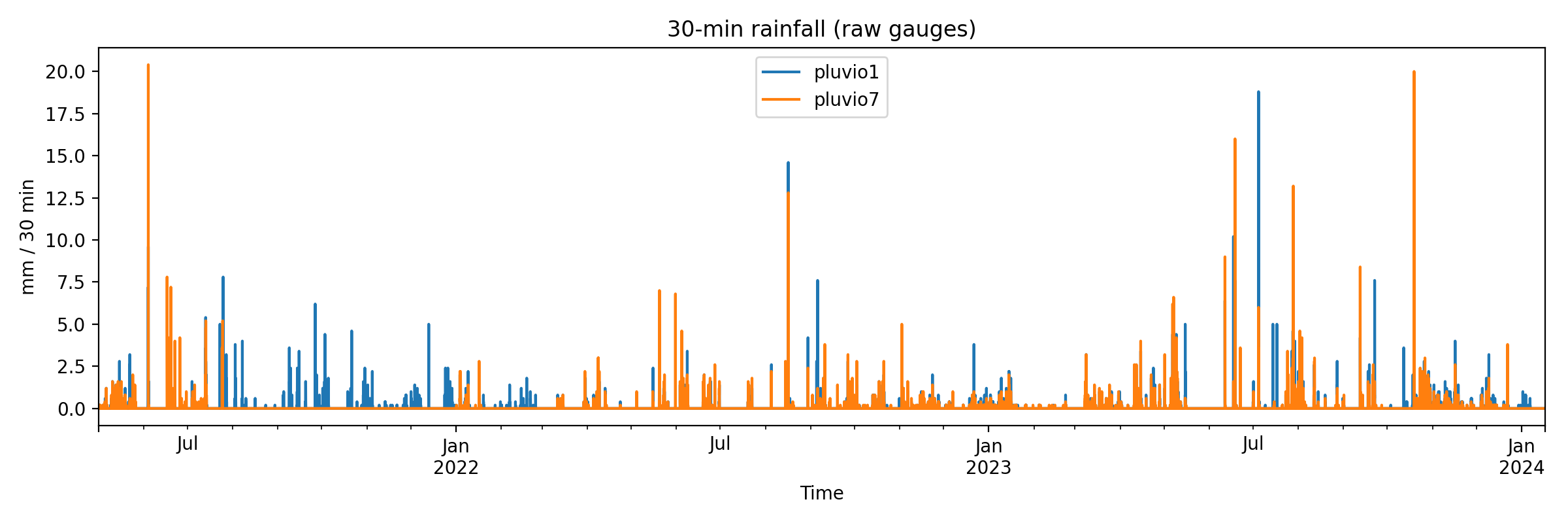
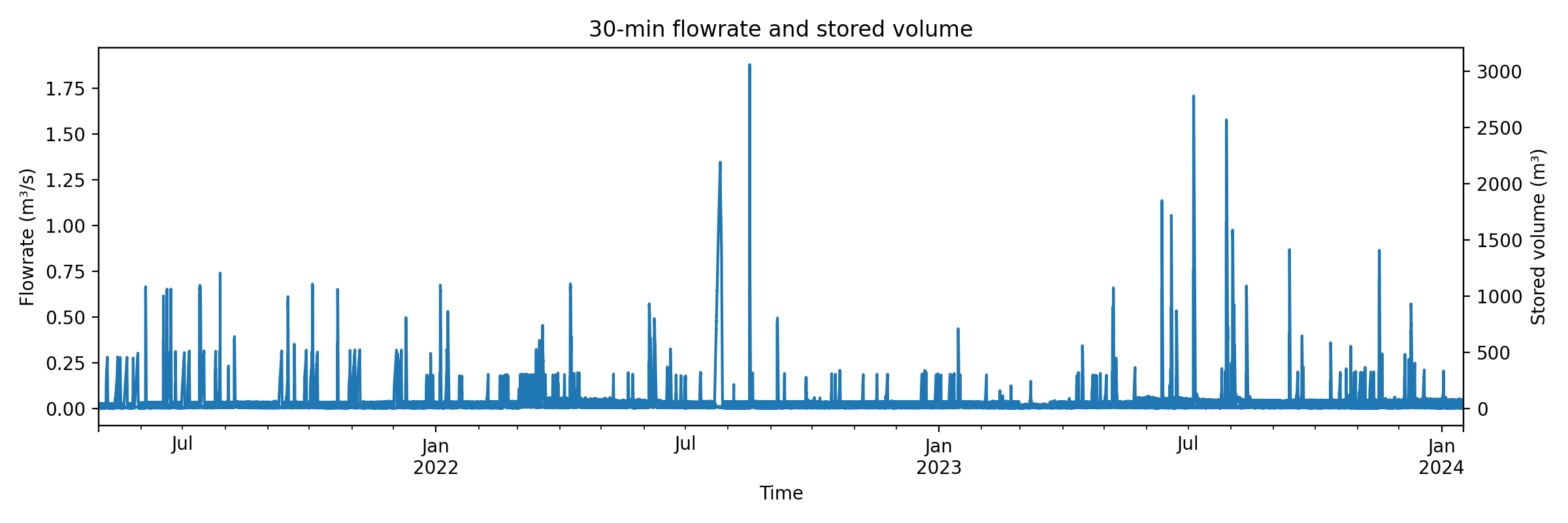
Technical Details
Stack & repository structure
├── scripts/
│ └── run_pipeline.py ← entry point (410 lines): load → clean → resample → export
├── src/ ← package modules (expand as workflow grows)
├── example_figures/
│ ├── rainfall_30min.png
│ ├── flow_and_storage_30min.png
│ └── qa_baseflow_rainflow_30min.png
├── Inputs/ ← place raw data here (git-ignored)
├── Outputs/ ← results written here (git-ignored)
├── requirements.txt
└── README.md
The pipeline is designed to be modular — each processing stage is a separate
function, making it easy to extend. The entry script run_pipeline.py currently implements
steps 1–2 (load, clean, resample, export). Steps 3–5 (rain marking, baseflow, flow separation)
are implemented as next modules in src/.